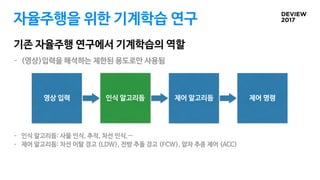
조엘 프라호드의 17시간 전, 5분 전 읽기 자율주행차는 곧 일상이 되고 우리는 이제 시작에 불과합니다. 만약 우리가 이러한 미래형 엔진을 만드는 방법을 이해하기 위해서는 이 모든 것을 가능하게 한 가장 관련 있는 기술을 이해해야 한다: 컴퓨터 비전.컴퓨터 비전은 자율주행차, 특히 환경에 대한 인식 속에서 어디에나 존재한다.카메라로 환경을 어떻게 인식하는가? 자율주행차의 컴퓨터 비전은 무엇인가?아래 이미지는 자율주행차 운행의 4가지 주요 단계를 보여줍니다.

- 컴퓨터 비전과 센서 융합은 지각이라고 불린다.그것은 환경을 이해하는 것에 관한 것입니다. 컴퓨터 비전은 카메라를 사용합니다. 이를 통해 자동차, 보행자, 도로 등을 식별할 수 있습니다. 센서 퓨전은 레이더나 라이다 등 다른 센서의 데이터를 사용하고 병합하여 카메라에서 얻은 데이터를 보완합니다.이를 통해 카메라로 식별된 객체의 위치와 속도를 추정할 수 있습니다.- 위치 파악은 GPS보다 더 정확하게 차를 찾을 수 있는 단계입니다.- 경로 계획은 자율주행차의 뇌를 실현합니다.경로 계획자는 처음 2단계 데이터를 사용하여 차량, 보행자 및 주변 물체가 A 지점에서 B 지점까지의 궤적을 생성하기 위해 무엇을 할 것인지 예측합니다.- 제어 장치는 컨트롤러를 사용하여 차를 작동시킵니다.
- 컴퓨터 비전 컴퓨터 비전 기술은 보행자나 다른 물체를 감지하기 위해 자율주행차에 사용되지만 이미지 이상을 발견하고 암을 진단하는 데도 사용된다.그들은 매우 고전적인 방법으로 선과 색을 감지하는 것에서 인공지능으로 갈 수 있습니다.컴퓨터 비전은 특정 물체의 형태를 묘사하는 1950년대에 시작됐다. 세기의 끝은 우리가 이미지에서 색의 진화를 구별할 수 있는 캐니 에지 검출과 같은 기술의 발전을 이끌었다.
2001년 비올라 존스 알고리즘은 컴퓨터가 얼굴을 인식하는 능력을 증명했다.
이듬해 머신러닝은 HOG(Histogram of Oriented Gradient)와 분류기를 널리 사용해 객체 검출로 대중화됐다. 목표는 다른 방향(글래디언트)을 인식함으로써 물체의 모양을 인식하도록 모델을 훈련시키는 것. 방향 그레이디언트의 히스토그램은 각 픽셀의 형태와 방향을 유지한 뒤 더 넓은 영역에 걸쳐 평균을 낸다.딥러닝은 강력한 GPU(그래픽 프로세서 유닛)의 등장과 데이터 축적으로 성능 면에서 큰 인기를 끌었다. GPU 이전에는 딥러닝 알고리즘이 우리 기계에서 작동하지 않았다.컴퓨터 비전은 3가지 방법으로 수행할 수 있다.- 인공지능 없이 모양과 색을 분석함으로써.- 기계학습으로 기능부터 학습 – Deep Learning에서는 혼자 배웁니다.
머신러닝 머신러닝은 컴퓨터 비전에서 형태를 식별하는 법을 배우는 데 사용되는 학문이다.학습에는 두 가지 유형이 있습니다.- 맵 학습을 통해 학습 데이터베이스에서 규칙을 자동으로 작성할 수 있습니다.우리는 다음을 구별한다.
a. 분류: 데이터가 한 클래스에 속하는지, 다른 클래스에 속하는지 예측합니다(예: dog 또는 cat). b. 회귀 분석: 다른 데이터를 기반으로 한 데이터를 예측합니다(예: 주택 크기 또는 우편 번호 기준 가격) 2. 비지도 학습은 유사한 데이터가 자동으로 함께 그룹화됨을 의미합니다.자동차 감지를 위한 지도학습 과정에는 4가지 단계가 있다.- 첫 번째는 자동차와 도로의 이미지 데이터베이스를 작성하는 것입니다. 지도 학습은 어떤 이미지가 자동차에 해당하고 어떤 이미지가 배경을 나타내는지 보여줍니다. 이것을 라벨링이라고 합니다.

2. 어떤 기능이 자동차에 속하는지 알아보기 위해 우리는 다른 색상의 공간에서 우리의 이미지를 시도한다. 우리는 HOG 기능을 사용하여 양식을 얻습니다. 이미지가 형상 벡터로 변환됩니다.

3. 이 벡터들은 서로 연결되어 훈련 기반으로 사용됩니다. 아래 그래프에서는 가로축과 세로축에 모양과 색상이 표시되어 있습니다.저희 반은 블루 포인트와 오렌지 포인트입니다. 우리는 또한 분류자를 선택해야 합니다.머신러닝 알고리즘은 특징에 따라 두 클래스를 구분하는 선을 그리는 것을 의미한다. 다음으로 선을 기준으로 한 위치에 따라 새로운 점(백십자)이 예측됩니다. 교육 데이터가 많을수록 예측은 정확해집니다.
4. 마지막 단계는 예측입니다. 화상을 통과하는 알고리즘을 구현하고 훈련에 사용되는 것과 동일한 기능을 갖는 벡터로 변환한다. 이미지의 각 부분이 분석되어 차량 주위에 경계 상자를 그리는 분류기에 전달됩니다.
머신러닝 알고리즘은 훈련에 사용될 기능을 선택할 수 있게 해준다.이러한 알고리즘은 오늘날 딥러닝과 신경망의 도래로 이미지 인식보다 데이터 조작에 더 많이 사용되고 있다. 또한 탐지가 느리고 많은 잘못된 긍정을 생성한다. 그것들을 제거하기 위해 우리는 많은 배경 이미지가 필요합니다.다음 연락처로 문의해 주세요.기홉